RAG Eval & Observe
Chat Interface that allows you to use, test and evaluate different strategies of Retrieval Augmented Generation
At a glance
- What it does
- Chat Interface that allows you to use, test and evaluate different strategies of Retrieval Augmented Generation
- Where it runs
- Runs in the browser
- Who it's for
- Anyone
Screenshots
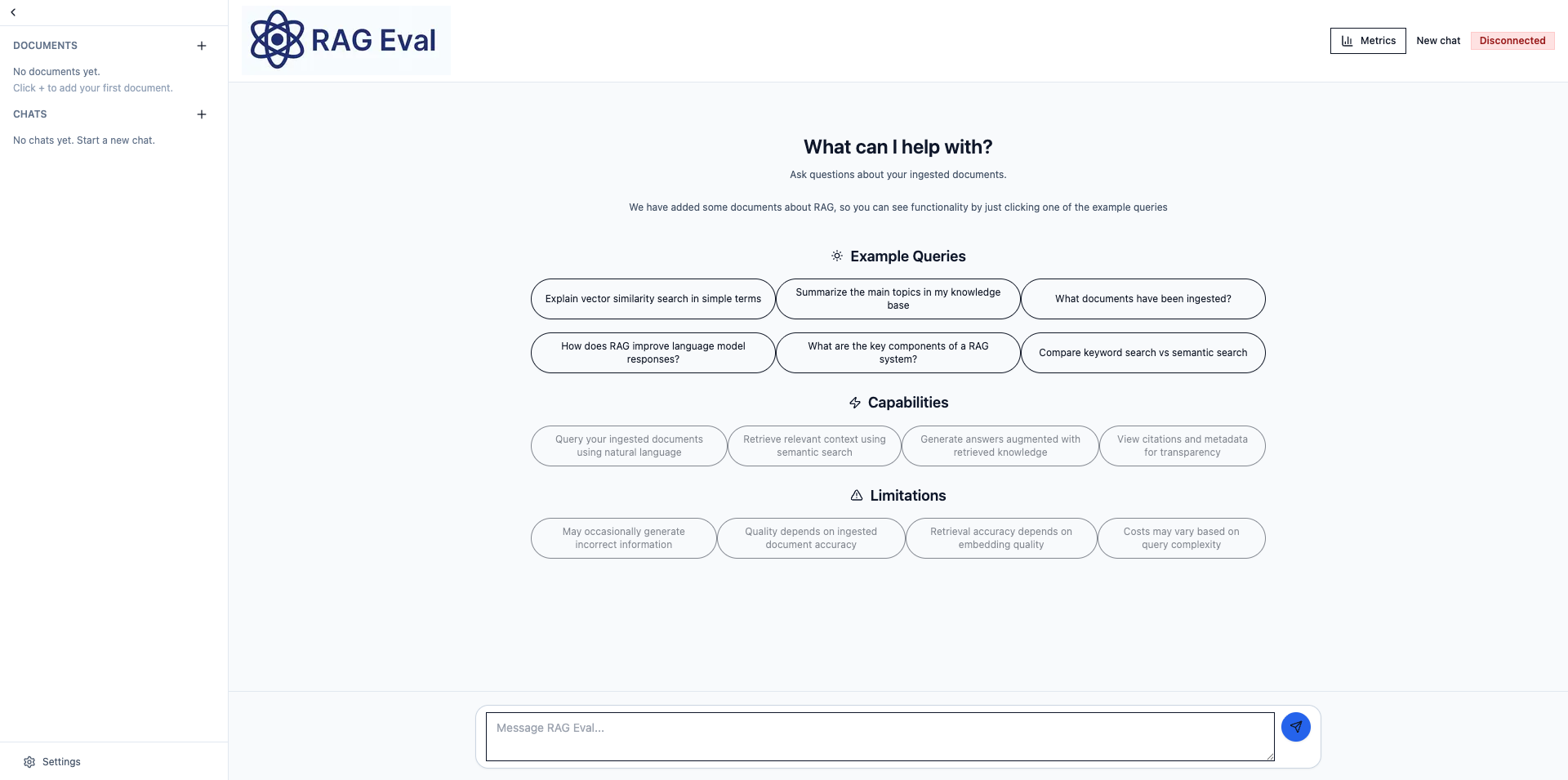
More details
More details coming soon.
How this is used
Personal Project, No day to day use
What it does
Overview
RAG Eval Observability is a full-stack platform designed to help developers and researchers build, test, and deploy production-ready RAG systems. It combines a modern web interface with a robust backend API, providing everything needed to ingest documents, query knowledge bases, and monitor system performance.
Key Capabilities
- Multiple RAG Strategies: Compare vector similarity search, hybrid search, reranking, and multi-query approaches
- Interactive Chat Interface: ChatGPT-style UI with citations, document previews, and structured answers
- Document Management: Upload and manage documents (text, PDF, DOCX) with chunk visualization
- Evaluation Framework: Offline evaluation harness with retrieval metrics and LLM-judge support
- Production Observability: Real-time metrics, health checks, and structured logging
- Enterprise Features: Rate limiting, distributed deployments, and comprehensive error handling
Why RAG Eval Observability?
Building production RAG systems requires more than just embedding and retrieval—you need tools to evaluate performance, monitor behavior, and iterate on improvements. This platform provides:
- Complete RAG Pipeline: End-to-end implementation from document ingestion to answer generation
- Multiple Retrieval Strategies: Experiment with different approaches to find what works best for your use case
- Production-Ready: Built with scalability, observability, and reliability in mind
- Developer-Friendly: Modern tech stack with TypeScript, FastAPI, and PostgreSQL
- Open Source: Fully open source with MIT license for maximum flexibility
Features
🔍 Advanced Retrieval Strategies
Choose from multiple RAG models optimized for different scenarios:
- Vector Similarity Search: Semantic search using cosine similarity on embeddings
- Hybrid Search: Combines vector search with BM25 keyword matching for improved recall
- Reranking: Uses a reranking model to improve retrieval accuracy
- Multi-Query RAG: Generates multiple query variations for better coverage
💬 Modern Chat Interface
- ChatGPT-Style UI: Clean, responsive interface optimized for conversation
- Structured Answers: Summary sections with expandable full answers
- Interactive Citations: Clickable citation markers with document references
- Document Preview: View document chunks directly from the sidebar
- Metadata Display: Cost, latency, and RAG model information for each response
📚 Document Management
- Multi-Format Support: Upload text files, PDFs, and DOCX documents
- Automatic Chunking: Intelligent document chunking with configurable overlap
- Chunk Visualization: Preview how documents are split into chunks
- Document Deletion: Remove documents with confirmation dialogs
📊 Observability & Monitoring
- Metrics Dashboard: Real-time system metrics including uptime, request counts, latency, and token usage
- Health Checks: Built-in health endpoints for monitoring and orchestration
- Structured Logging: Request IDs and detailed error logging for debugging
- Cost Tracking: Monitor API costs with token usage breakdowns
🧪 Evaluation Framework
- Offline Evaluation: Test RAG performance without production traffic
- Retrieval Metrics: Hit@K and Mean Reciprocal Rank (MRR) calculations
- LLM Judge: Optional LLM-based evaluation for correctness and faithfulness
- Report Generation: Automated evaluation reports with failure examples
Send a signal to the creator
Lightweight signals help creators understand what resonates — no comments, no rankings.